Wie finde ich ein bestimmtes Bild wieder? Das Durchstöbern zahlreicher Ordner auf der Festplatte kann sehr müßig werden, insbesondere wenn der Bildbestand auf mehrere Zehntausend Bilder angewachsen ist. Die Suche wird stark vereinfacht, wenn die Bilder in einer Datenbank beschrieben werden, mit Informationen zum Ort und dem Tag der Aufnahme sowie einer möglichst genauen Beschreibung des Bildinhaltes.
Allerdings: Nicht das (Aus-) Sortieren der unterwegs gemachten Bilder oder deren Nachbearbeitung mit Programmen wie Lightroom oder Photoshop verschlingt die meiste Zeit. Den größten Arbeitsaufwand verursacht die eingangs erwähnte textuelle Beschreibung der Bilder.
Während das Datum und der Ort der Aufnahme schnell festgestellt sind, braucht die Beschreibung des Bildinhalts mehr Zeit. Fortschritte gibt es auch hier: Mit Webseiten wie Wikipedia und wikimapia geht die inhaltliche Recherche einfacher und schneller im Vergleich zu den früher verwendeten Stadtplänen und Reiseführern. Zusätzliche, sogenannte Metainformationen, fehlen dann noch immer. Meinen Versuch dies „von Hand“ zu machen, habe ich vor Jahren aufgegeben. Es war das berühmte Fass ohne Boden. (Um was es sich bei Metainformationen handelt, wird im Laufe dieses Textes klar, hoffe ich.)
Cloud-Dienste zur Bildanalyse
Eine Möglichkeit Bildbeschreibungen mit Metainformationen anzureichern, ermöglichen Cloud-Dienste wie sie die IT-Riesen Google, Microsoft und Amazon anbieten. Wie funktionieren Google Vision, Microsoft Cognitive Services und Amazon Rekognition?
Allen Cloud-Diensten gemeinsam ist, dass sie für unterschiedliche Programmiersprachen Programmierschnittstellen anbieten. Ich nutze als Programmierumgebung das auf JavaScript basierte node.js. Um die genannten Cloud-Dienste nutzen zu können ist eine Anmeldung bei diesen erforderlich. Für eine gewisse Zeit bzw. für einen gewissen Umfang ist die Nutzung der Dienste frei, danach fallen Gebühren an.
Nachfolgend skiziere ich kurz die Funktionsweise der drei genannten Cloud-Dienste. Eine ausführliche Dokumentation findet sich auf den Webseiten von Google Cloud, Microsoft Azure und Amazon Web Services.
Google Vision
Nach der Anmeldung in der Google Cloud erhält man zur Nutzung der angebotenen Dienste eine Credential-Datei credential.json, die man seinem System über die Umgebungsvariable GOOGLE_APPLICATION_CREDENTIALS bekannt macht. Zur Nutzung mit node.js muss das Paket @google-cloud/vision installiert werden. Die Grundstruktur des node.js-Programms ist sehr kurz:
const vision = require('@google-cloud/vision');
const client = new vision.ImageAnnotatorClient();
var request = {
image: { source: { filename: '1202064.jpg' } },
features: [{ type: "LABEL_DETECTION", maxResults: 20 }]
};
client.annotateImage(request).then(results => {
const labels = results[0].labelAnnotations;
labels.forEach(label => console.log(label.description + '|' + Math.round(label.score * 1000.0)));
}
Zurück bekommt man eine Liste von Labels, die jeweils mit einem Score bewertet werden. Der Score hat einen Wert zwischen 0 und 1. Um so höher dieser Score ist, desto sicherer ist das Google-System, dass dieser Label auch korrekt ist. Für eine bessere Übersichtlichkeit multipliziere ich den Score mit 1000. Beispiele zu Labels und Scores finden sich weiter unten.
Microsoft Cognitive Services
Bei Microsoft Azure erhält man Zugriff auf die Programmierschnittstellen durch alphanumerische Schlüssel, die direkt im Programmcode verwendet werden können. Für das node.js-Programm muss das Paket azure-cognitiveservices-vision installiert werden.
const Vision = require('azure-cognitiveservices-vision');
const CognitiveServicesCredentials = require('ms-rest-azure').CognitiveServicesCredentials;
let credentials = new CognitiveServicesCredentials('xxx');
let computerVisionApiClient = new Vision.ComputerVisionAPIClient(credentials, "westeurope");
let result = computerVisionApiClient.analyzeImage(
'https://www.juergen-reichmann.de/images/pics/1202000/1202064.jpg',
{ visualFeatures: ['Tags'] },
function (err, result) {
const tags = result.tags;
tags.forEach(tag => console.log(tag.name + '|' + Math.round(tag.confidence * 1000.0)));
}
);
Was bei Google Labels sind, wird bei Microsoft als Tag bezeichnet. Inhaltlich ist es das gleiche. Der dem Google-Score-Wert entsprechende Confidence-Wert eines Tags liegt zwischen 0 und 1 (und wird für die nachfolgende Vergleichbarkeit auf Werte zwischen 0 und 1000 skaliert).
Amazon Rekognition
Der Amazon Web Service bietet wie Google eine Credential-Datei um auf seine Dienste zugreifen zu können. Diese wird an einem bestimmten Ort – unter Linux ist dies ~/.aws/credentials – auf seinem lokalen Rechner hinterlegt.
Google und Microsoft bekommen die Daten des zu analysierenden Bildes entweder über eine URL (im Beispiel „https://www.juergen-reichmann.de/images/pics/1202000/1202064.jpg“) oder durch direkten Upload der Bilddatei zur Verfügung gestellt. Geringfügig komplizierter gestaltet sich der Vorgang bei Amazon. Hier muss die entsprechende Bilddatei zuerst im Amazon-eigenen Simple Storage Service (S3) gespeichert werden.
Zur Verwendung mit node.js wird das Paket aws-sdk benötigt.
const AWS = require('aws-sdk');
AWS.config.update({region: 'us-east-1'});
const rekognition = new AWS.Rekognition();
const fs = require('fs');
const s3 = new AWS.S3();
const bucketName = 'rekog-upload-3';
var bucketParams = { Bucket: bucketName };
function base64_encode(file) {
var bitmap = fs.readFileSync(file);
return new Buffer(bitmap).toString('base64');
}
s3.createBucket(bucketParams, function(err) {
var s3Bucket = new AWS.S3( { params: {Bucket: bucketName} } );
var imageName = '1202064';
var data = { Key: imageName, Body: Buffer.from(base64_encode('1202064.jpg'), 'base64') };
s3Bucket.putObject(data, function(err, data){
var params = {
Image: { S3Object: { Bucket: bucketName, Name: imageName } },
MaxLabels: 100,
MinConfidence: 20
};
rekognition.detectLabels(params, function(err, data) {
const labels = data.Labels;
labels.forEach(label => console.log(label.Name.toLowerCase() + '|' + Math.round(label.Confidence * 10.0)));
});
});
});
Bei Amazon heißt der Label Label wie bei Google, die Bewertung desselbigen Confidence wie bei Microsoft. Allerdings liegt der Confidence-Wert bei Amazon zwischen 0 und 100.
Allen drei hier vorgestellten Cloud-Diensten gemeinsam ist, dass sie ihre Ergebnisse auf Englisch zurückliefern. Benötigt man die Ergebnisse in einer anderen Sprache, lassen sich diese beispielsweise mit der Google Cloud Translation API automatisiert übersetzen.
Beispiele
Um die Qualität der drei Bildanalysedienste beurteilen zu können, habe ich Beispielbilder mit unterschiedlichen Motiven ausgewählt. Die Ergebnisse (und mehr noch meine Schlussfolgerungen) haben aufgrund der geringen Stichprobenauswahl keinen wissenschaftlichen Anspruch, liefern aber interessante Erkenntnisse. Bei Google und Amazon tauchen nur Labels (Tags) auf, die einen Scorce- bzw. Confidence-Wert von größer als 500 haben.
Beispiel 1: High Street und Carfax Tower Oxford
Eine Straßenszene in der englischen Universitätsstadt Oxford, eingerahmt von historischen Bauten.

High Street und Carfax Tower Oxford
| Microsoft | Amazon | ||||||
|---|---|---|---|---|---|---|---|
| town | 917 | building | 1000 | architecture | 829 | ||
| city | 897 | outdoor | 1000 | building | 829 | ||
| sky | 828 | sky | 991 | city | 829 | ||
| urban area | 812 | road | 976 | downtown | 829 | ||
| town square | 797 | street | 959 | plaza | 829 | ||
| medieval architecture | 787 | people | 926 | town | 829 | ||
| building | 786 | walking | 899 | town square | 829 | ||
| street | 784 | city | 841 | urban | 829 | ||
| history | 696 | group | 585 | clock tower | 675 | ||
| tourist attraction | 621 | way | 565 | tower | 675 | ||
| metropolis | 598 | square | 539 | crowd | 634 | ||
| facade | 594 | crowd | 486 | human | 634 | ||
| tower | 594 | town | 398 | person | 634 | ||
| plaza | 586 | gathered | 308 | bell tower | 569 | ||
| bell tower | 556 | pedestrians | 264 | landscape | 520 | ||
| middle ages | 548 | day | 101 | nature | 520 | ||
| steeple | 548 | outdoors | 520 | ||||
| tourism | 547 | scenery | 520 | ||||
| tours | 518 | cathedral | 518 | ||||
| château | 512 | church | 518 | ||||
| worship | 518 | ||||||
| castle | 517 | ||||||
| road | 510 | ||||||
| street | 510 |
Sofort auffallend ist die hohe Qualität der Ergebnisse. Bis auf wenige Ausnahmen sind die gefundenen Labels korrekt.
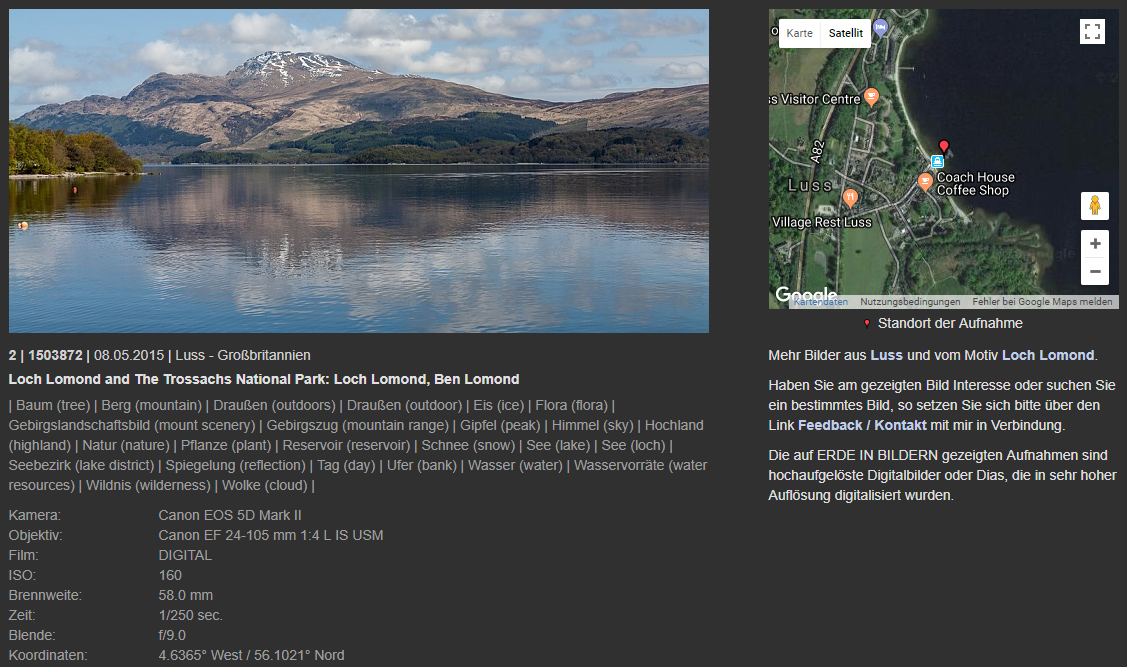
Beispiel 2: Loch Lomond and The Trossachs National Park
Ein gänzlich anderes Motiv: Ein Landschaftsbild aus Schottland.

Loch Lomond and The Trossachs National Park
| Microsoft | Amazon | ||||||
|---|---|---|---|---|---|---|---|
| reflection | 978 | mountain | 999 | lake | 977 | ||
| water | 963 | outdoor | 998 | outdoors | 977 | ||
| nature | 951 | water | 996 | water | 977 | ||
| lake | 950 | sky | 993 | mountain | 562 | ||
| loch | 933 | nature | 955 | mountain range | 562 | ||
| mountain | 917 | lake | 919 | nature | 562 | ||
| sky | 917 | pond | 566 | peak | 562 | ||
| highland | 906 | surrounded | 533 | glacier | 527 | ||
| wilderness | 892 | day | 120 | ice | 527 | ||
| reservoir | 866 | snow | 527 | ||||
| fjord | 809 | flora | 512 | ||||
| mountain range | 791 | grass | 512 | ||||
| cloud | 785 | plant | 512 | ||||
| lake district | 782 | ||||||
| fell | 779 | ||||||
| mount scenery | 746 | ||||||
| tree | 736 | ||||||
| bank | 733 | ||||||
| water resources | 724 | ||||||
| river | 706 |
Auch in diesem Beispiel ist die Trefferquote sehr hoch. Es bestätigt sich der Eindruck von Beispiel 1, dass die Ergebnisliste von Microsoft im Vergleich zu den beiden Konkurrenten deutlich kürzer ist.
Beispiel 3: Berlin-Pankow
Wiederum eine völlig andere Bildsituation. Diesmal eine Luftbildaufnahme aus einem Berliner Außenbezirk.

Berlin-Pankow
| Microsoft | Amazon | ||||||
|---|---|---|---|---|---|---|---|
| aerial photography | 974 | outdoor | 996 | aerial view | 993 | ||
| urban area | 967 | sky | 987 | landscape | 993 | ||
| city | 951 | mountain | 727 | nature | 993 | ||
| bird's eye view | 934 | overlooking | 548 | outdoors | 993 | ||
| metropolitan area | 920 | scenery | 993 | ||||
| suburb | 917 | building | 884 | ||||
| residential area | 819 | urban | 884 | ||||
| photography | 808 | freeway | 871 | ||||
| metropolis | 805 | road | 871 | ||||
| cityscape | 778 | city | 868 | ||||
| urban design | 764 | town | 868 | ||||
| sky | 752 | downtown | 798 | ||||
| skyline | 566 | architecture | 676 | ||||
| building | 556 | housing | 676 | ||||
| monastery | 676 | ||||||
| campus | 629 | ||||||
| brick | 628 | ||||||
| neighborhood | 606 | ||||||
| office building | 601 | ||||||
| intersection | 569 | ||||||
| castle | 566 | ||||||
| house | 566 | ||||||
| mansion | 566 | ||||||
| palace | 566 | ||||||
| court | 548 | ||||||
| apartment building | 527 | ||||||
| high rise | 527 | ||||||
| park | 526 | ||||||
| plaza | 522 | ||||||
| town square | 522 | ||||||
| countryside | 518 | ||||||
| flora | 518 | ||||||
| plant | 518 | ||||||
| conifer | 513 | ||||||
| tree | 513 | ||||||
| yew | 513 | ||||||
| metropolis | 511 | ||||||
| convention center | 509 | ||||||
| fence | 508 | ||||||
| hedge | 508 | ||||||
| field | 508 |
Die Microsoft-Ergebnisliste ist mit Abstand am kürzesten, nur vier Labels wurden gefunden, einer davon – mountain – nicht nachvollziehbar, ein weiterer – sky – nur bedingt relevant. Auch der Luftbild-Charakter – bei Google und Amazon jeweils die Nummer 1 auf der Liste – detektiert Microsoft nicht. Daneben fällt die sehr lange Liste von Amazon auf. Ihre inhaltliche Qualität lässt erst am Ende etwas nach. Die Wertungen dort sind allerdings auch nicht mehr sehr hoch.
Beispiel 4: Wembley-Stadion London 2013
Eine Szene mit jubelnden Spielern des FC Bayern München nach dem Gewinn des Champion League Finales im Londoner Wembley-Stadion.

Wembley-Stadion (Wembley Stadium) London 2013: Nach dem UEFA Champions League Finale FC Bayern München – Borussia Dortmund
| Microsoft | Amazon | ||||||
|---|---|---|---|---|---|---|---|
| sport venue | 985 | grass | 1000 | human | 993 | ||
| team sport | 970 | person | 972 | people | 993 | ||
| stadium | 949 | field | 962 | person | 993 | ||
| sports | 944 | soccer | 961 | trophy | 991 | ||
| player | 941 | outdoor | 890 | mascot | 989 | ||
| canadian football | 920 | group | 675 | football | 962 | ||
| football player | 890 | sport | 668 | soccer | 962 | ||
| ball game | 888 | grassy | 629 | sport | 962 | ||
| team | 876 | football | 242 | sports | 962 | ||
| grass | 845 | team | 962 | ||||
| gridiron football | 839 | team sport | 962 | ||||
| structure | 832 | crowd | 542 | ||||
| soccer specific stadium | 776 | flora | 524 | ||||
| plant | 770 | grass | 524 | ||||
| competition event | 768 | plant | 524 | ||||
| games | 765 | clothing | 508 | ||||
| tournament | 759 | hat | 508 | ||||
| soccer | 696 | ||||||
| american football | 676 | ||||||
| arena | 654 |
Google liegt in der Anzahl der Labels vorne, allerdings sind ein paar davon nicht korrekt (canadian football, gridiron football, american football).
Beispiel 5: Times Square New York bei Nacht
Das besondere an diesem Beispielbild ist, dass es bei Nacht entstanden ist.

Times Square New York City
| Microsoft | Amazon | ||||||
|---|---|---|---|---|---|---|---|
| metropolitan area | 986 | building | 994 | human | 987 | ||
| metropolis | 960 | street | 979 | people | 987 | ||
| city | 958 | outdoor | 979 | person | 987 | ||
| night | 955 | night | 931 | building | 745 | ||
| urban area | 950 | city | 895 | city | 745 | ||
| landmark | 942 | walking | 777 | town | 745 | ||
| cityscape | 931 | busy | 350 | urban | 745 | ||
| infrastructure | 863 | crowd | 5 | silhouette | 745 | ||
| neon sign | 848 | downtown | 705 | ||||
| neon | 838 | architecture | 575 | ||||
| downtown | 799 | plaza | 575 | ||||
| skyscraper | 784 | town square | 575 | ||||
| street | 778 | metropolis | 520 | ||||
| electronic signage | 750 | night life | 518 | ||||
| lighting | 739 | high rise | 516 | ||||
| darkness | 656 | road | 514 | ||||
| tourist attraction | 621 | street | 514 | ||||
| sky | 552 | poster | 508 | ||||
| advertising | 552 | ||||||
| building | 517 |
Den nächtlichen Charakter der Aufnahme erkennen alle, bei der Anzahl der Labels liegen Google und Amazon wieder deutlich vor Microsoft. Völlige Fehlinterpretationen finden sich bei keinem.
Praktische Anwendung
Fotografieren und Reisen sind zwei Dinge, die mir sehr wichtig sind. Fotografieren geht schon auch mal ohne auf einer Reise zu sein. Aber eine Reise ohne einen Fotoapparat, dieser Gedanke fällt mir sehr schwer (und alle, die jemals mit mir unterwegs waren, können ein Lied davon singen…).
Nach einer Vorkontrolle des aufgenommenen Bildmaterials, wird dieses thematisch auf Ordner meiner heimischen Festplatte verteilt. Diese Themen bilden die Grundlage dessen, was ich später auf meiner Webseite als Bilderserie bezeichne. Den Inhalt eines solchen Themenordners bearbeite ich mit Adobe Lightroom (selten kommt noch Adobe Photoshop zur Anwendung) nach. Die Nachbearbeitung hat keine inhaltlichen Bildänderungen zur Folge, vielmehr korrigiere ich schiefe Horizonte, schneide etwas an den Bildrändern ab und erhöhe den Kontrast von zu flauen Bildern. Das eine oder andere Bild wandert auch noch in die digitale Mülltonne.
Sind die Bilder eines Themenordners komplett bearbeitet, kommt der schreibende Teil. Jedes (nicht-gelöschte und nachbearbeitete) Bild bekommt dabei einen Eintrag in meiner Bilddatenbank. Dazu gehört eine eindeutige Bildnummer (die ich seit meinem allerersten Dia fortschreibe), eine Referenz auf die digitale Bilddatei, Datum und Ort der Aufnahme sowie Informationen zum gezeigten Inhalt (beispielsweise „High Street und Carfax Tower“ in Beispielbild 1). Parallel lese ich die technischen Information der Bilder (wie Belichtungszeit, Blende, ISO-Wert, GPS-Daten) aus den sog. EXIF-Daten der Aufnahmen und lege diese Information ebenfalls in der Bilddatenbank ab.
Für die Veröffentlichung auf einer meiner Webseiten wandern die ausgewählten Bilder – wie schon erwähnt – in eine Bilderserie. Das Beispiel des Oxford-Bildes liegt in der Serie „Oxfordshire – Oxford 1“. Jede solche Serie wird einem Land (in diesem Fall „Großbritannien“) oder einem Themenkomplex zugeordnet.
Ist eine Serie komplett, kommen die hier vorgestellten Cloud-Dienste zum Einsatz. Ich lasse alle Bilder einer Serie von diesen analysieren. Die detektierten Labels – dabei handelt es sich um die anfangs erwähnten Metainformationen – kontrolliere ich abschließend von Hand. Labels, die ich nicht für geeignet halte, entferne ich.

Entfernung von falsch detektierten Labels
Abschließend wandern die Bilder zusammen mit den beschreibenden Information auf meine Webseite.
Webseite mit Bild und umfangreichen Informationen
Zusammenfassung
Die Qualität der Bilderkennung der hier vorgestellten Cloud-Dienste von Google, Microsoft und Amazon hat mich positiv überrascht. Sie liefern eine Menge an zusätzlicher (Meta-) Information zu einem Bild und das mit einer erstaunlich hohen Treffsicherheit. In der Anzahl der gefundenen Labels fällt Microsoft gegenüber seinen Mitbewerbern zurück. Obwohl die Trefferanzahl bei Google und Amazon ähnlich ist, sind ihre inhaltlichen Schwerpunkte leicht unterschiedlich.
Die Nutzung der Programmierschnittstellen gestaltet sich – zumindest bei Nutzung von node.js – als einfach. Die benötigte Dokumentation ist nicht immer einfach auf den Webseiten von Google, Microsoft und Amazon zu finden, da täte an der einen oder anderen Stelle etwas mehr Ordnung gut. Man spürt deutlich, dass die Cloud-Welt ein sehr schnell wachsendes Geschäftsfeld ist. Hat man die entsprechende Webseite gefunden (am besten gleich bookmarken!), sind die Informationen aber ausführlich und verständlich.
Bei den Diensten handelt es sich um selbstlernende Systeme, d.h. ihre Ergebnisqualität soll sich im Laufe der Zeit allein durch die Anzahl der analysierten Bilddaten verbessern. Interessant wird sein, in einem gewissen zeitlichen Abstand die Beispielbilder erneut analysieren zu lassen und die Ergebnisse mit den hier vorgestellten zu vergleichen.